martes, 11 de junio de 2013

Aprendizaje no supervisado
Este tipo de aprendizaje no necesita que le mostremos los patrones objetivo para salida, ya que el algoritmo y la regla de modificación de las conexiones producen patrones de salida consistentes. Cuando la red procesa patrones con bastante grado de similitud, da la misma salida para ambos patrones, esto es, clasifica los patrones en categorías de patrones parecidos.
Podemos imaginar que en el proceso de aprendizaje, la red mide cuanto se parecen el patron que le llega y los que tiene almacenados y en función de ello los agrupa en una categoría o otra, aunque en un principio no sepamos que salida corresponderá a cada tipo o grupo de patrones de entrada, ni que atributos usará para clasificarlos. Esto es, nosotros solo tenemos un conjunto de patrones no sabemos ni las características ni las categorías posibles y la red en función de su algoritmos de aprendizaje diferenciara ambas cosas y nos clasificara los patrones en categorías.
En general, los métodos de aprendizaje no supervisado usan representaciones modélicas de los objetos a reconocer y a clasificar. Por ejemplo una aplicación de reconocimiento de caras podríamos pasar la fotografía como un mapa de bits pero esto seria muy costoso computacionalmente, pero sin embargo si pasáramos una serie de valores como anchura de ojos, anchura de boca, tamaño de frente, etc., esto nos podría clasificar la cara en función de sus parecidos.
Entre los distintos tipos de aprendizaje no supervisado podemos distinguir, el aprendizaje por componentes principales y el aprendizaje competitivo.
a) Aprendizaje por componentes principales
El aprendizaje por componentes principales se basa en hallar características principales a (componentes) que son comunes a muchos patrones de entrada para ello un pequeño número de neuronas coopera en la representación del patrón de entrada.
b) Aprendizaje competitivo
En el aprendizaje competitivo, las neuronas pugnan entre sí, para representar a una clase o patrón de entrada.
La neurona seleccionada es aquella cuyos pesos incidentes se asemejan más al patrón de entrada. El aprendizaje consiste en reforzar las conexiones de la unidad ganadora y debilitar las otras, para que los pesos de la unidad ganadora se asemejen cada vez más al patrón de entrada.
La reconstrucción de un patrón de entrada a partir de una neurona ganadora consiste en tomar el peso de dicha neurona ya que son los valores que más se asemejan.
c) Aprendizaje reforzado
La base de este aprendizaje es muy parecida al aprendizaje supervisado pero la información que proporcionamos a la red es mínima se limita a indicar si la respuesta de la red es correcta o incorrecta.
Este tipo de aprendizaje se basa en la noción de condicionamiento por refuerzo, esto es se aprenden las conductas reforzadas positivamente y las conductas castigadas o reforzadas negativamente. En nuestro mundo esto se traduce en premiar los pesos sinápticos cuando se acierta la salida y penalizarlos cuando no se acierta.
Aprendizaje supervisado en redes neuronales

En este en modo aprendizaje se muestran los patrones a la red y la salida deseada para esos patrones y se usa una fórmula matemática de minimización del error que ajuste los pesos para dar la salida más cercana posible a la salida deseada.
Un esquema general de este tipo de aprendizaje sería este:
1. Inicializar los pesos de las sinapsis aleatoriamente.
2. Para cada patrón P perteneciente al conjunto de los patrones que tenemos
2.1 Mostrar el patrón de entrada Pentrada y hacer la dinámica de la red para calcular la salida de la red Sred, que no es la salida deseada sino un patrón aleatorio ya que los pesos inicialmente eran aleatorios.
2.2 Hallamos el error Cálculo del error entre la salida de la red, Sred, y la salida deseada del patrón Psalida_deseada. Esto se hace en muchos casos con el error cuadrático medio Epatrón = Raizcuadrada(suma((Psalida_deseadai) ² - (Sredi) ²)).
2.3 Ajustar los pesos usando la regla de aprendizaje para disminuir el error medio. Normalmente, se hace creando una función que represente el error cometido, la cual derivamos para aplicar la técnica de minimización matemática.
Otra forma de ver los procesos de ajuste de los pesos, es como un mapa bidimensional que representa los errores que la red comete en la clasificación, en función de los pesos u las entradas. El objetivo es llegar lo más bajo posible en el mapa, para ello, buscamos la gradiente para cada punto concreto de ese mapa. Para ello derivamos la función error para encontrar la dirección de máxima pendiente. Quizás esta parte es la más compleja matemáticamente.
En resumen usaremos una función, que demostrada matemáticamente por alguno de los anteriores principios, minimiza el error entre la salida que deseamos Psalida_deseada y la salida que nos da la red Sred.
3. Si el error es mayor de cierto criterio volver al paso 2; si todos los ejemplos sehan clasificado correctamente, finalizar.
Las redes más significativas que usan este aprendizaje supervisado son el Perceptrón, El Perceptrón multicapa y la red de Hopfield.
Algunas de sus aplicaciones más importantes son:
Asociadores de patrones, esto es asocia dos patrones y permite recuperar la información a pesar de errores en la capa de entrada.
Modeladores funcionales, las redes neuronales permiten, gracias a su capacidad de ajustar el error dar los valores más cercanos a una función de la que solo sabemos algunos puntos por los que pasa
Como ejemplo de aprendizaje supervisado podemos observar, el perceptron, el cual tiene la siguiente función de aprendizaje
Psiguiente = Pactual + x* (Psalida_deseada – Sred) * Pentrada
Donde Psiguiente es el nuevo valor para el peso sináptico, Pactual es el peso actual, x es un parámetro que permite definir cuanto de rápido aprende la red, Psalida_deseada es la salida que deseamos para esa entrada, Sred es la salida que ha generado la red y Pentrada es el patrón de entrada.
Esta regla aplicada iterativamente a todos los patrones de entrada hace que los pesos converjan a un estado en el que darán Psalida_deseada cuando le presentemos el patrón Pentrada o uno que sea lo suficientemente parecido a el.
¿Que son las redes neuronales? y un poco de historia

Las redes de neuronas artificiales (denominadas habitualmente como RNA o en inglés como: "ANN"1 ) son un paradigma de aprendizaje y procesamiento automático inspirado en la forma en que funciona el sistema nervioso de los animales. Se trata de un sistema de interconexión de neuronas que colaboran entre sí para producir un estímulo de salida. En inteligencia artificial es frecuente referirse a ellas como redes de neuronas o redes neuronales.
Historia:

Los primeros modelos de redes neuronales datan de 1943 por los neurólogos McCulloch y Pitts. Años más tarde, en 1949, Donald Hebb desarrolló sus ideas sobre el aprendizaje neuronal, quedando reflejado en la "regla de Hebb". En 1958, Rosemblatt desarrolló el perceptrón simple, y en 1960, Widrow y Hoff desarrollaron el ADALINE, que fue la primera aplicación industrial real.

En los años siguientes, se redujo la investigación, debido a la falta de modelos de aprendizaje y el estudio de Minsky y Papert sobre las limitaciones del perceptrón. Sin embargo, en los años 80, volvieron a resurgir las RNA gracias al desarrollo de la red de Hopfield, y en especial, al algoritmo de aprendizaje de retropropagación ideado por Rumelhart y McLellan en 1986 que fue aplicado en el desarrollo de los perceptrones multicapa.
Propiedades:
Una red neuronal se compone de unidades llamadas neuronas. Cada neurona recibe una serie de entradas a través de interconexiones y emite una salida. Esta salida viene dada por tres funciones:
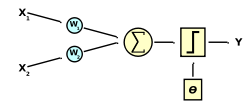
- Una función de propagación (también conocida como función de excitación), que por lo general consiste en el sumatorio de cada entrada multiplicada por el peso de su interconexión (valor neto). Si el peso es positivo, la conexión se denomina excitatoria; si es negativo, se denomina inhibitoria.
- Una función de activación, que modifica a la anterior. Puede no existir, siendo en este caso la salida la misma función de propagación.
- Una función de transferencia, que se aplica al valor devuelto por la función de activación. Se utiliza para acotar la salida de la neurona y generalmente viene dada por la interpretación que queramos darle a dichas salidas. Algunas de las más utilizadas son la función sigmoidea (para obtener valores en el intervalo [0,1]) y la tangente hiperbólica (para obtener valores en el intervalo [-1,1]).
Suscribirse a:
Comentarios (Atom)